Zhong Zhong

I'm graduate student who has a strong interest in Machine Learning and Data Analysis. I also study Deep Learning (especially, computer vision) during my free time.
笨鸟先飞 & 耐心
This is my review of EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks
This paper systematically studied model scaling and identified that carefully balancing network depth, width and resolution can lead to better performance. It proposes a new simple but effective compound coefficient that can be used to uniformly scale all dimensions of depth, width, and resolution. To go even further, a baseline model is designed and scaled up to obtain a family of models, called EfficientNets. EfficientNets achieve better accuracy and efficiency (a order of magnitude fewer parameters and FLOPS) than previous ConvNets.
Outline:
-
Motivation
-
Compounding Scaling
-
Architecture
-
Experiments
-
lass Activation Map (CAM)
1 Motivation
Previous studies have shown that scaling up the network dimensions can improve model accuracy. However, most of them only tried to scale one of the dimensions, either depth, width or resolution, others tried to arbitrarily scale two or three dimensions, which require tediout manual tuning and often yield sub-optimal accuracy and efficient. The this paper aimed to rethink the scaling process and investigate if there is a principled method to scale up Convnets that can achieve better accuracy and efficient.
2 Compounding Scaling
Two observations about scaling up the dimensions. First, scaling up any dimensions of network depth, width, or resolution improves accuracy, but the accuracy gain diminishes for bigger model. Second, it is critical to balance all dimensions of network width, depth, and resolution during ConvNet scaling.
Compound scaling method uniformly scales network width, depth, and resolution in a principled way.
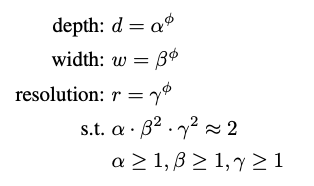
Because convolution ops usually dominate the computation cost in ConvNets, alpha is not squared by 2 here. φ is a user-specified coefficient that controls how many more resources are available.
3 Architecture
In order to better demonstrate the effectiveness of the scaling method, a new mobile-size baseline model was developed, call EfficientNet by leveraging a multi-objective neural architecture search that optimizes both accuracy and FLOPS. The baseline architecture is similar to MnasNet, whose building block is mobile inverted bottleneck MBConv (increase dimension first and reduce it back to input size). Also, squeeze-and-excitation optimization is added to the buidling block.
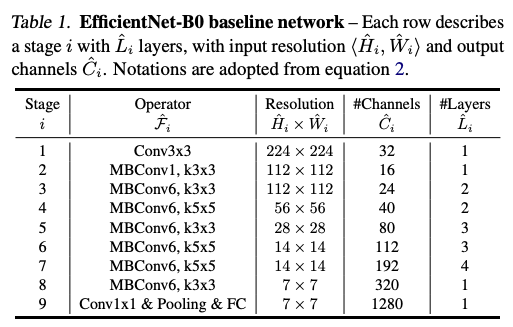
The compound scaling method is used to scale up EfficientNet-B0
STEP 1: we first fix φ = 1, assuming twice more resources avalible, and do a small grid research of these values.
STEP 2: these three values are set to be fixed, and scaled up with different φ, thus EfficientNet-B1 to B7 are obtained.
4 Experiments
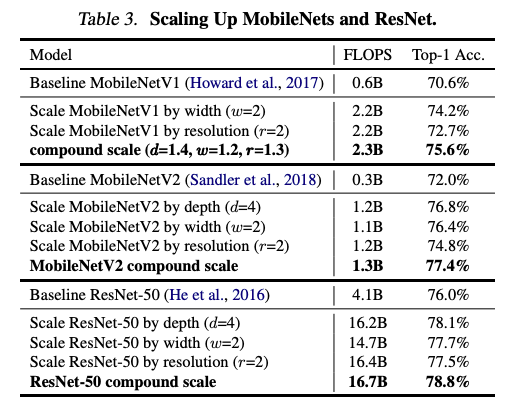
- Scaling up MobileNets and ResNets
The compound scaling method is first applied to existing ConvNets, MobiltNet and ResNets. Models with compound scaling method achieve better accuracy while maintaining similar FLOPs, compared to existing ConvNets with no or only single dimension scaling.
- ImageNet Results for EfficientNets
One thing should be noticed is that some fancy training setting are used to train EfficientNets on ImageNet, such as RMSProp optimizer, SiLu activation, AutoAugment, and stochastic depth, etc. EfficientNet models generally use an order of magnitude fewer parameters and FLOPs than other ConvNets with similar accuracy. Moreover, some experiments also have been done to test the validate latency. The evidence shows that EfficientNets are indeed fast.

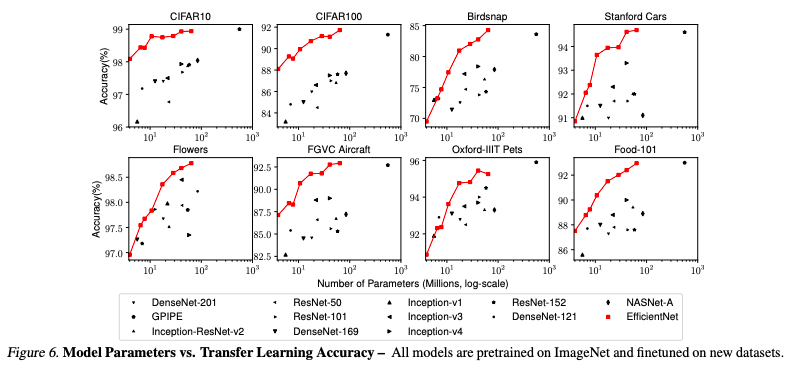
- Transfer learning results for EfficientNets
EfficinetNets are pretrained on ImageNet and fintune on new datasets, then applied to various of tranfer learning datasets. The results show that EfficientNets consistently achieve better acuracy with an order of magnitude fewer parameters than existing models.
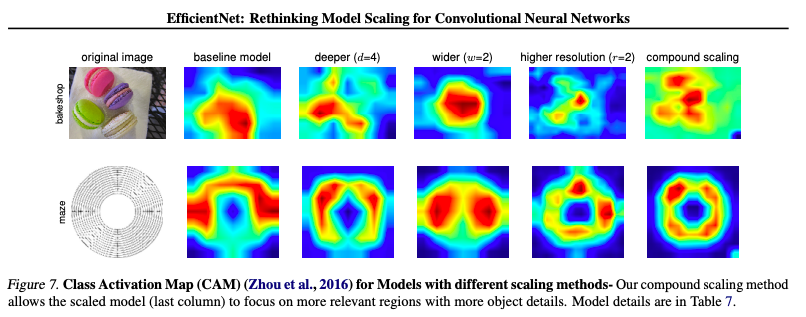
5 Class Activation Map (CAM)
CAM is used to visualize the effectiveness of the compound scaling method. EfficientNet-B0 is scaled up with single-dimension or compound method, models with compound scaling tend to focus on more relevant regions with more object details, while other models are lack of object details or unable to capture all objects in the image.
Understand how they propose the compound coefficient.
FLOPS (floating-point operations in # of multiply-adds)