Zhong Zhong

I'm graduate student who has a strong interest in Machine Learning and Data Analysis. I also study Deep Learning (especially, computer vision) during my free time.
笨鸟先飞 & 耐心
This is my review of SqueezeNet
Former research focused on improving CNNs accuracy. Smaller CNNs offer at least three advantages: 1. smaller CNNs require less communication across servers during distributed training. 2. smaller CNNs require less bandwidth to export a new model from the cloud to an autonomous car. 3. smaller CNNs are more feasible to deploy on FPGAs and other hardware with limited memory. SqueezeNet is proposed to achieve all these advantages. SqueezeNet can achieve AlexNet-level accuracy on ImageNet with 50x less parameters. In addition to comparable accuracy and light weight, the model is less than 0.5MB, 510x smaller than AlexNet.
1 Motivation
Unlike former CNN models, the paper intended to identify a CNN model with fewer parameters while still maintaining comparable accuracy to popular architectures, since smaller architectures have several advantages as follows.
-
More efficient distributed training. Small models require less communications and train faster.
-
Less overhead (operating costs) when exporting new models to clients. Smaller models require large data transfers.
-
Feasible FPGA and embedded deployment. A sufficiently small model can be stored directly on the FPGA.
2 Fire Moudle
The paper outlined several design strategies for CNN architecture with few parameters.
-
Strategy 1 Replace 3x3 filters with 1x1 filters. 1x1 filter has 9x less parameter than 3x3 filter.
-
Strategy 2 Decrease the number of input channels to 3x3 filters.
-
Strategy 3 Downsample late in the network so that convolution layer have large activation maps. The intuition is that large activation maps can lead to higher classification accuracy.
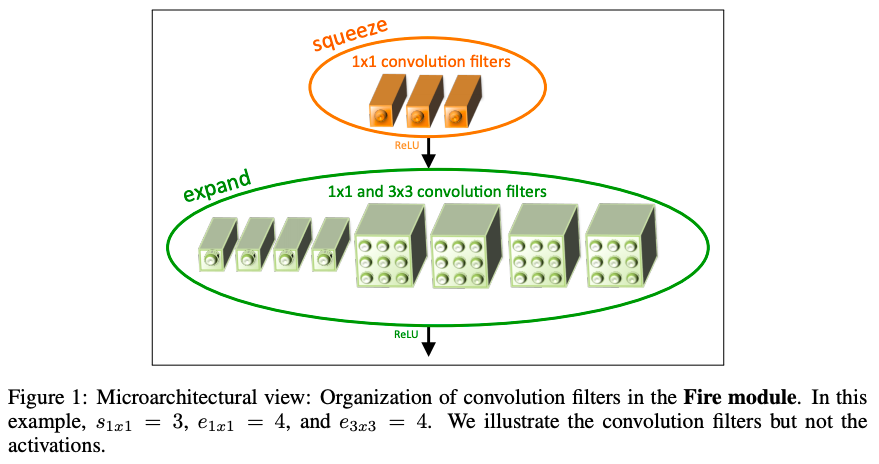
A fire moudle consists of a squeeze convolution layer (which only has 1x1 filters). The squeeze conv is feeding into an expend layer that has a mix of 1x1 layer and 3x3 layer.
There are three tunable dimensions in a fire moudle: s1x1, the number of 1x1 filters in squeeze layer; e1x1, the number of 1x1 filters in expand layer; e3x3, the number of 3x3 filters in expand layer. s1x1 is set to be smaller than (e1x1+e3x3) to reduce the number of parameters.
3 Baseline SqueezeNet
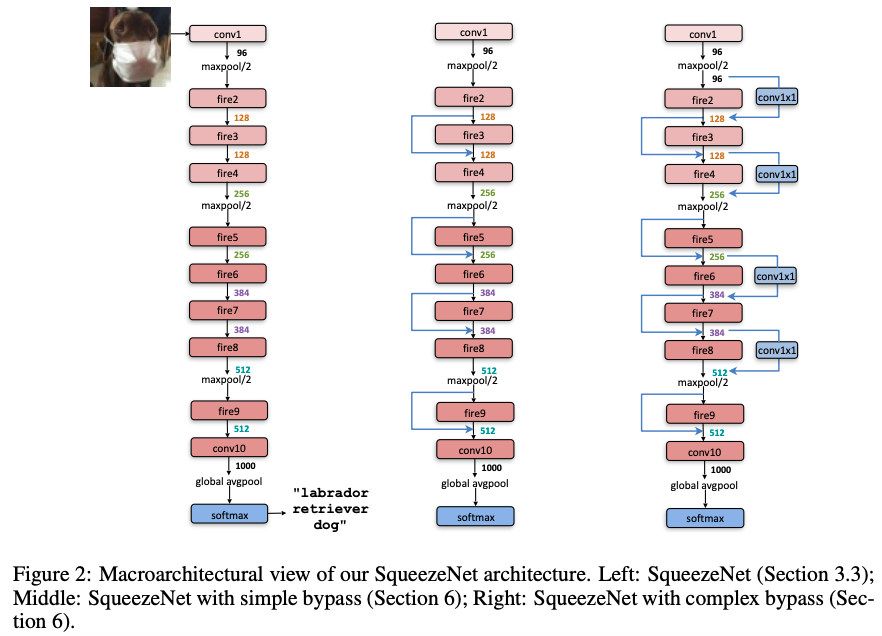
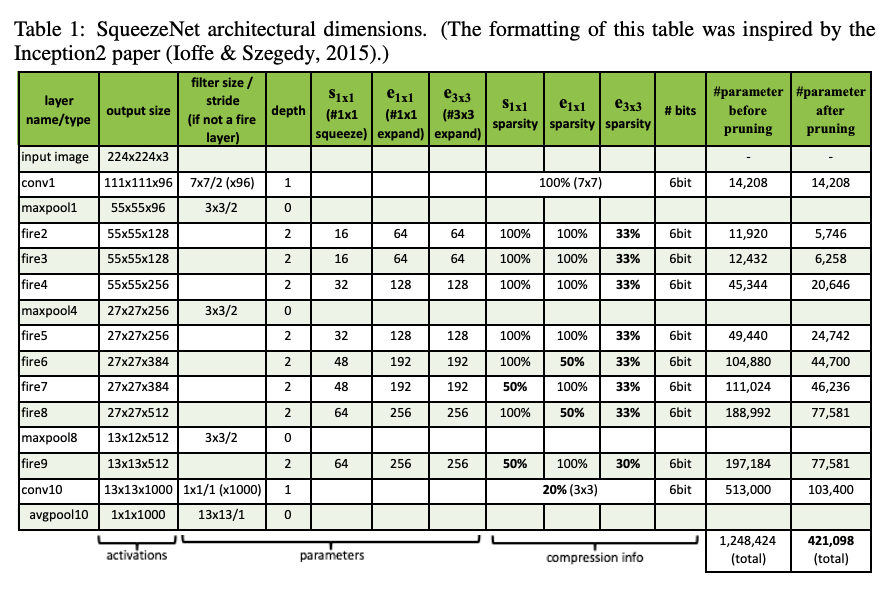
The SqueezeNet is basically a stack of fire modules. The number of channels in the fire module graduatelly increases. The max pooling layers are not placed mostly in late layers to increase the representational power of the network and model accuracy.
More details about SqeezeNet
1x1 and 3x3 have the same spatial output size.
Dropout (0.5) is applied after the 9th fire module.
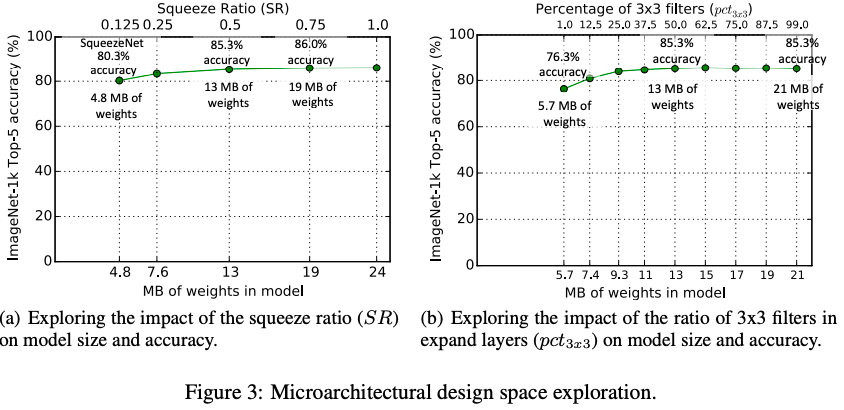
4 Microarchitecture design space exploration
Change the number of channels and adjust the fire module structure
The ratio of 3x3 filters in expand layers:
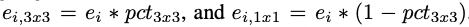
Squeeze ratio: the ratio between the number of filters in squeeze layers and the number of filters in expand layers. SR is in the range [0, 1], shared by all fire modules in the network.
5 Macroarchitecture design space exploration
Addnig skip connections
Vanilla SqueezeNet.
SqueezeNet with simple bypass connections between some fire modules.
SqueezeNet with complex bypass connections between remaining fire modules.
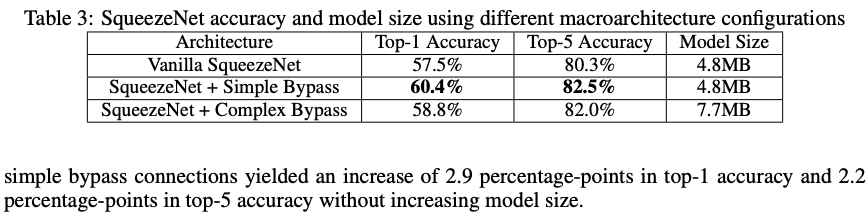
Model with bypass connections outperform ordinary SqueezeNet.

[x] Code
[ ] Example