Zhong Zhong

I'm graduate student who has a strong interest in Machine Learning and Data Analysis. I also study Deep Learning (especially, computer vision) during my free time.
笨鸟先飞 & 耐心
The is my review of MobileNetV1
MobileNet is a light weight deep neural network that is specifically designed for mobile and embedded vision applications. This streamlined architecture is constructed by repeating the depthwise separable convolution. Two hyperparameters, width multiplier and resolution multiplier are also introduced in order for developers to control the size of the network. MobileNets primarily focus on optimizing for latency but also yield small networks.
Small size and fast networks are advantageous to various real world applications. In order to build small and efficient networks, any different approaches were proposed. All these methods can be categorized as follows. One approach is to shrink, factorize or compress pretrained networks. Another method is distillation, which uses a larger network to teach a smaller network. Another emerging approach is low bit networks.
1 Depthwise Separable Convolution
Depthwise Separable Convoluton consists of two parts: depthwise convolution and pointwise convolution. Depthwise convolution (a) is first used to filter only one input channel. Then, pointwise convolution (c), a simple 1x1 convolution is used to combine the output of depthwise convolution. Of course, nonlinearity and BN are applied in both depthwise and pointwise layer.
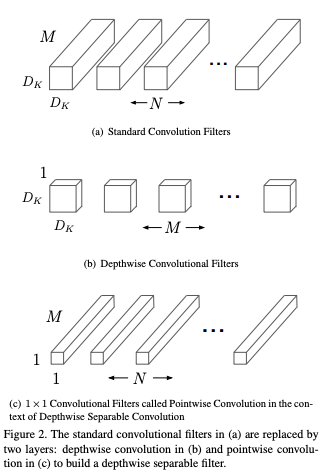

The conventional convolution layer cost;
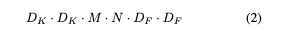
Depthwise convolution has computational cost of:
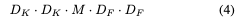
Depthwise separable convolution has computational cost of:
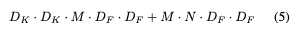
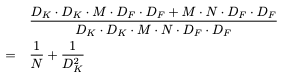
2 Network Structure
MobileNet is simply built on stacking the depthwise separable convolution.
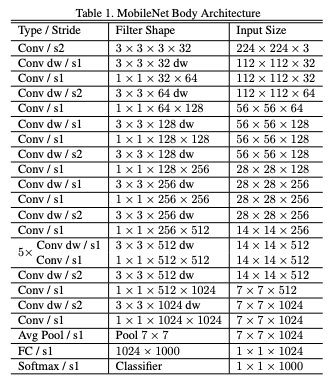
3 Width Multiplier α for thinner models
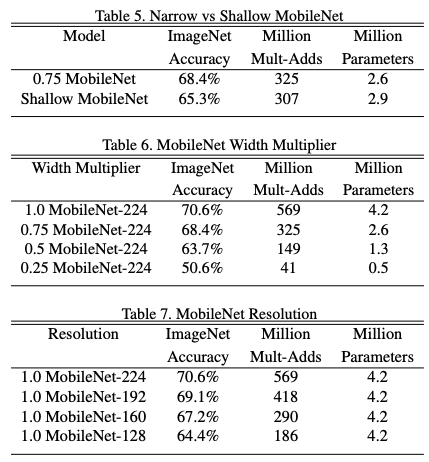
Width multiplier α is introduced to control, more specifically, thin the input width and output width (number of feature channel) of a layer. The number of input channel becomes αM and the number of output channel becomes αN. α is smaller than 1 but larger than 0, typical 1, 0.75, 0.5 and 0.25. α = 1 is the baseline MobileNet, α < 1 is the reduced MobileNet. With the α, the computational cost and the number of parameters can be reduced quadratically by roughly α^2. It is used to define new reduced structure with comparable accuracy and better size that needs to be trained from scratch.
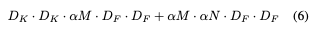
4 Resolution Multiplier ρ for reduced representation
ρ is another hyperparameter that can be usd to reduce the computational cost. ρ is used to multiply the image resolution, and it is typically set implicitly so that the input resolution of the network is 224, 192, 160 or 128. ρ has the effect of reducing computational cost by ρ^2.
The computational cost after adding the two hyperparameter:
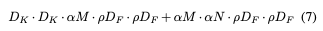
5 Experiments
MobileNets compare to SOTA
MobileNets have much less parameters and mult-adds than popular networks, while mantaining comparable accuracy.
MobileNets with shrinking hyperparameter
Fine grained recoginition
Large scale geolocalization
Face attributes
Object Detection
Face Embeddings
Question I need to figure out:
-
Does reduced MobileNet have same α and ρ through all the layers?
-
Width multiplier reduces the number of channels. So is it like dropout, only here it sets the whole feature map to zero.