Zhong Zhong

I'm graduate student who has a strong interest in Machine Learning and Data Analysis. I also study Deep Learning (especially, computer vision) during my free time.
笨鸟先飞 & 耐心
This is my review of Densely Connected Convolutional Networks
DenseNet is a followup of ResNet, because it further extends the idea of shortcut connections between layers in the network. In DenseNet, each layer is connected to all the subsequent layers in a feedfoward fashion. Network with L layers, there will be L(L+1)/2 connections. With this dense connection, DenseNet can achieve high performance with better computation and parameter efficiency. Densenet also alleviate the vanishing gradient problem and encourage feature reuse.
Outline:
-
Motivation
-
DenseNet Architecture
-
Advantages
-
Experiment
-
Conclusion
1. Motivation
ResNet and other architecture have shown that shortcut connection can improve convolutional networks accuracy and efficiency. They obeserve this idea and further study it.
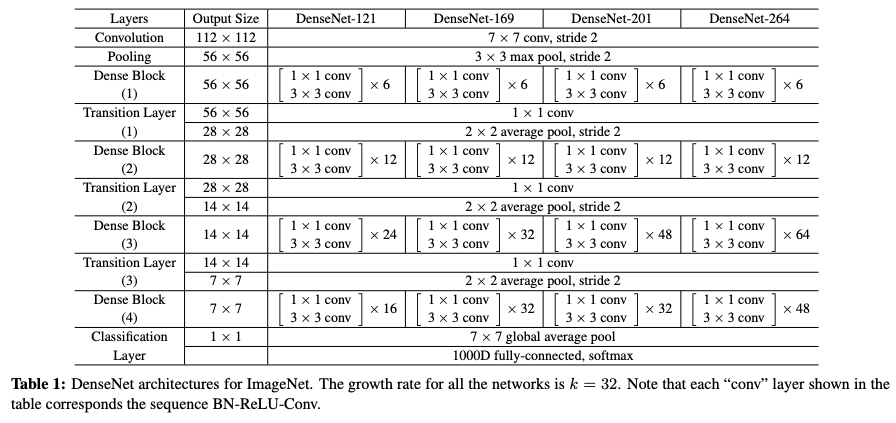
2. DenseNet Architecture
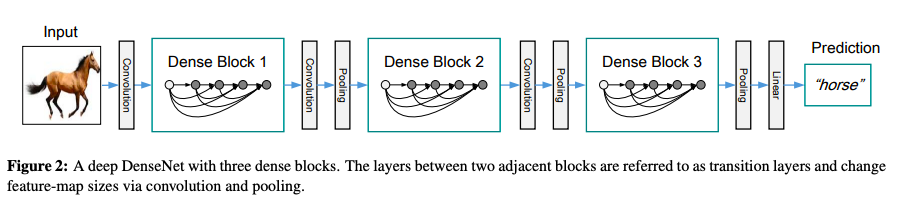
Dense Connectivity
Unlike the sparse connectivity between layers in ResNet, DenseNet adpoted dense connectivity, in which each layer is connected with all other layers. All preceding feature maps from former layers are used as input into a layer, and all its output feature maps are used as input into its subsequent layers.
Another important novel feature in DenseNet is that it concatenates all the feature maps from earlier layers, not summing like in ResNet. Each layer receives “collective knowledge” from preceding layers.
Basic DenseNet Composition Layer
Three operations are included in each composition layer, batch normalization, rectified linear unit (ReLu) and 3x3 convolution (conv).
Transition layer
In order to use different filter sizes (smaller), transition layer is used to downsample layers to the feature map size of the next dense block. Transition layer consists of batch normalization, 1x1 convolution layer and 2x2 average pooling layer.
Growth Rate
Growth rate (k) is the number of new feature maps added by each layer within a dense block.
DenseNet-B
DenseNet-b is a variant of baseline DenseNet. Except all the features above, DenseNet-B introduces the 1x1 convolution layer (BN-ReLu-1X1 Conv) before each composition layer (BN-ReLu-3x3 conv). It is referred to as bottleneck layer and reduces the number of input feature maps of each composition layer. The output of each bottleneck is set to 4k (k is the growth rate).
DenseNet-C
In order to further improve the model efficiency and compactness, a compression factor θ is added in the model. Say a dense block produces m features (why here do use k? isn’t k = m), the following transition layer generates θm features, where θ < 0. In DenseNet-C, θ is set to 0.5.
DenseNet-BC
When compression factor θ (θ < 0) is used to both bottleneck layer and transition layer, the DenseNet model is referred to as DenseNet-BC.
3. Advantages
Strong Gradient Flow
Layers have access to gradient from the loss function more directly, it helps train the model and makes the model more difficult to overfit.
Parameter & Computational Efficiency
The growth rate, k, can be very small, however, the DenseNet model can still achieve outstanding performace. Another reason why DensetNet is efficient is because it uses both bottleneck and transition layers.
More Diversified Features
Because each layer receives all the feature maps from earier layers, it provides the layer more diversified features.
Maintains Low Complexity Features
In tranditional convolutional network, the classifer usually makes predictions with complex features, since later conv layers consists of high levels features. Whereas, in DenseNet, classifer uses features at all complexity levels.
4. Experiment
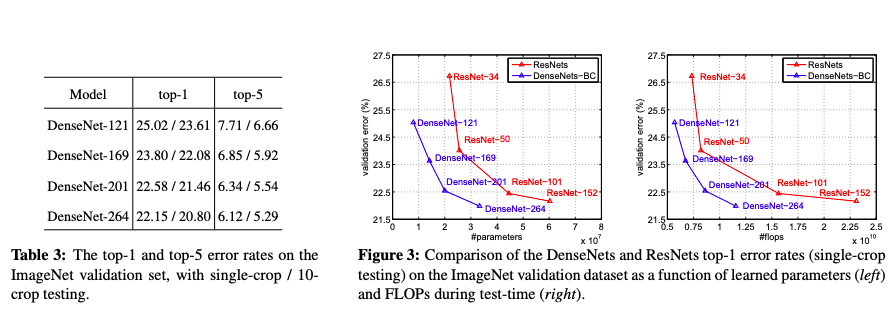
Results on CIFAR10, CIFAR100, and SVHN.
Results on ImageNet.
5. Conclusion
With the dense connectivity, DenseNet can very easily avoid overfitting and the vanishing gradient problem. As the number of layer increases, DenseNet can achieve SOTA on most of the benchmark datasets more efficiently. DenseNets integrated with properties of deep supervision, diversified depth and feature reuse are more accurate and can be used on various computer vision tasks.
-
Code
-
Add different DenseNet architectures.