Zhong Zhong

I'm graduate student who has a strong interest in Machine Learning and Data Analysis. I also study Deep Learning (especially, computer vision) during my free time.
笨鸟先飞 & 耐心
This is my review of the paper, ImageNet Classification with Deep Convolutional Neural Network

Paper summary: This paper proposed a convolutional neural network, AlexNet, which was the deepest convolutioanl network back in 2012. AlexNet consists of eight layers, five convolution layer and three fully connected layers. It achieved outstanding performance with top-5 error rate and top-1 error rate of 15.3% and 26.2%, which helped them win the first place in 2012 ImageNet Competition. It outperformed the architecture in the second place by more than 10% in accuracy.
1. Introduction
The paper first started with introducing how the increased size of image dataset helped the development of powerful models in vision learning. Simple recognition tasks can be solved well with just samll size dataset, such as MNIST, Caltech, and CIFAR-10/100, it is, however, hard to build successful models on tasks in realistic setting. Recently, it has been possible to collect labeled data with millions of images, one example is the ImageNet dataset.
After that, the paper explained why convolutional network is useful in training data with the such size as ImageNet. In general, there are a few reasons. Convolutional network captures the spatial feature of the images, unlike fully connnect network, it actually satisfies the assumption about the nature of iamges, pixels close to each other usually have similar values. Locally connection which helps CNNs achieve better performance on images can significant reduce the number of parameters in the model, thus less computation will be required.
2. Novel features
Several novel feataures are used in order to train such a large model at that time. These features improved both training speed and model accuracy.
- ReLu Nonlinearity
Traditional activation function, such as logistic function and tanh function, saturate at both ends of the function. AlexNet uses an nonsaturating activation function, ReLu, proposed by Hintom and Nair, it was found that ReLu can significantly improve the training speed.
- Training on multiple GPUs
Due to the computational resouce limitations, they proposed a new training implementation method, in which they used parallelization training with two GPUs. They claimed that this method can not only hlep train such a large network but also improve the performance. (Group convolution)
-
Overlapping Pooling
Pooling layer summarizes the neighboring neurons, more importantly, it reduces the number of parameters in the network. They found that during training models with overlapping pooling tend to be more difficult to overfit.
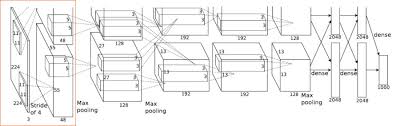
3. The Architecture
The architecture has eight weighted layers. The last fully connected layer is a softmax layer. Response normalization layers follow the first and the second conv layer. Max pooling layer follow the first and second conv layer as well as the fifth conv layer.
ReLu is applied to the output of every conv layer and fully connected layer.
The input is 224x224x3.
First convoltional layer, filter size 11x11x3, stride 4, 96 kernels.
Second convolutional layer, filter size 5x5x48, 256 kernels.
Third conv layer, filter size 3x3x256, 384 kernels. (be careful filter size here, it is because of the implementation method)
Fourth conv layer, filter size 3x3x192, 384 kernels.
Fifth conv layer, filter size 3x3x192, 256 kernels.
4. Reducing Overfitting
5. Results
AlexNet achieved the state-of-the-art performance on the ImageNet dataset in 2012. They also built an emsamble of CNN models which outperformed former SOTAs on different versions of ImageNet datasets.
They displayed how CNNs can be invariant to object being in different positions in a image.
6. Conclusion
This paper shows that CNNs can be capable of achieving record-beating results on image recognition tasks.
Also, there is evidence that the depth of the CNN is vital for it to achieve high performance.